AI: Absent Introspection
For the past few days it has felt “off-topic” to write or think about anything other than the attacks on free speech in the U.S. But I don't have a framework – yet – for writing about that, and I do have a close-reading framework for thinking about the ways AI encourages us to think about and use it.
When I say AI I'm shorthanding for “GenAI,” or generative AI – take your pick of chatbots like ChatGPT or image generation systems like DALL-E. I'll be using examples primarily from ChatGPT because it's still the most well-known brand-name AI, but most of the underlying principles are common to all AI – yes, even your favorite, yes, even ChatGPT4 or 5, yes, even the ones that promise to be significantly “better” than previous models. This is a way to understand what the project of AI is and does, even if you aren't an advanced computer scientist.
Let's begin by setting the stage. In close reading of literature, I might introduce the conventions of the genre, or discuss relevant biographical details. Here, let's get on the same page about what GenAI is. And since I like to let the text speak for itself, here's ChatGPT describing its own epistemology: How does it “know” things?
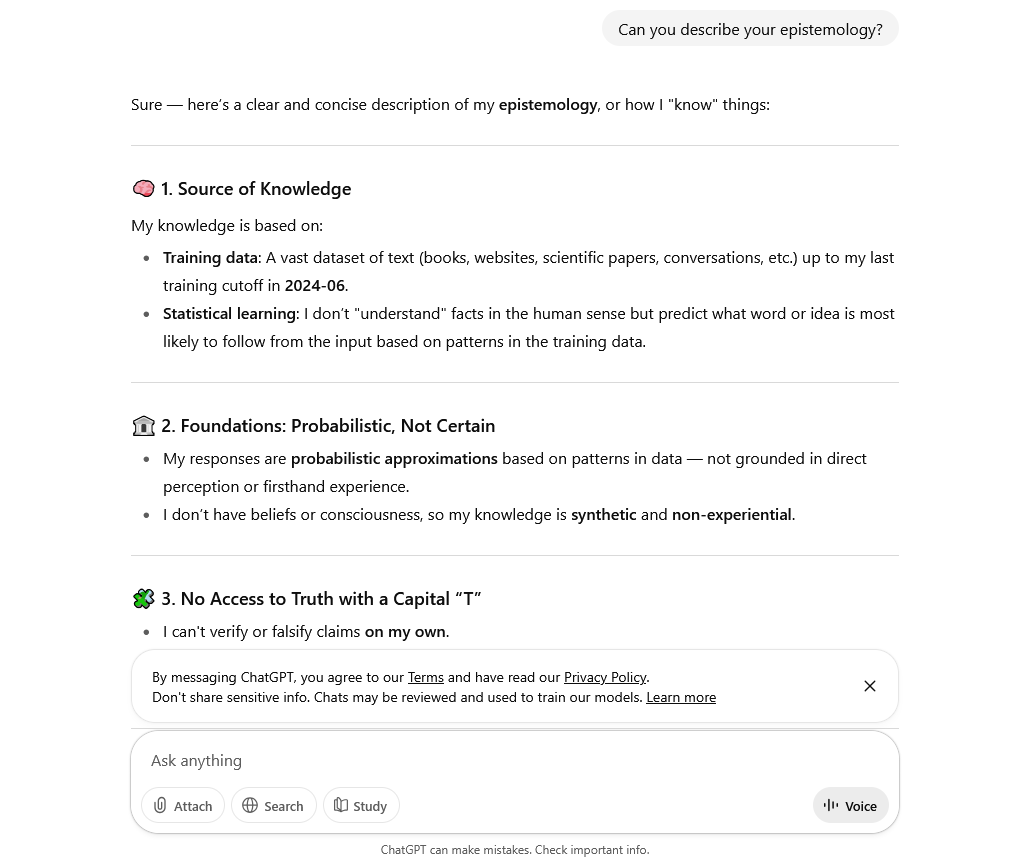
Generative AI is a predictive algorithm that uses extremely large (and no, not always “publicly available”) datasets as context to predict the next word in a sequence. By this laborious process – which is a clue as to why the technology is so incredibly resource-intensive – it constructs answers to queries that both trawl and curate available information and present it to the user in a facsimile of human speech. Rather than getting a list of relevant search results (and don't get me started on how “relevancy” in search results algorithms has been a slow and steady bait-and-switch) you are given a paragraph of “speech” as if a friend is explaining the concept to you.
This speech is prioritized and shaped by a training system. This part is very vague and heavily policed by the companies that control each AI, so it's tough to get specifics, but here is ChatGPT with a reasonable summary of how it works (I cut off the first part, which is essentially “crunching a big dataset on its own, by trying to predict a word and then checking against a source to adjust for loss”):

(I want to be clear, since it would be very silly of me, that I'm not taking ChatGPT at its word here. I've done my own research over the last few years on how GenAI works and this is consistent and sufficient for an investigation into the way its “knowledge” is both produced and professed to be “knowledge,” even if the picture is not technically precise. If you want to learn more about the computer science of it all, I recommend Emily Bender's work on computational linguistics.)
It's natural to pause here and consider: How did the companies, and the individual computer scientists, who developed GenAI decide on this approach? In what ways is it a natural outgrowth of their access to, and immense pressure to monetize, large datasets? How does it reflect a “computer science epistemology,” that is, a way of understanding the production of knowledge that is informed by the methods and the deemed-important questions of the field of computer science? And how did this all come to be labeled “intelligence”?
I encourage you to think more about these questions, and would love to hear your thoughts. In the meantime, let's keep focus on just the process by which AI produces “knowledge.” By predicting the next word in a sentence – and let's acknowledge that of course its analytical process is more contextual than that, so it's really predicting the next word in a sentence within a paragraph within a query that points it to a knowledge-base – it is necessarily a synthesis-machine. It will take what it can analyze and attempt to find a word – read, an answer – of best fit, defined as a combination of most-popular (the parameters set by its first round of training) and most-desired (the parameters of its second round of human-mediated training – who are the reinforcers and what is their epistemology, by the way?).
It is a predictor of the middle-way and then, worse, it parses that middle way into approximate, predictive text. And this is a best-case scenario, if it works perfectly – even though, as a necessary consequence of a predictive process, hallucinations are going to be a feature and not a bug in the system.
Does that process describe critical thinking? Does that process align with your own ideas of what it means to produce knowledge? Sometimes, when what you want is not knowledge but an approximation of general feeling, that might be a reasonable way to go about it – though, of course, you're allowing a dangerous distance between your own ideas of what “approximation” and “feeling” mean for veracity and what the AI presents to you. But in its own way, that's not necessarily harmful, if we do as we are told and “double-check important info.” However, in the next post I will discuss how the rest of the apparatus in these screenshots, not to mention the way AI is discussed and economically incentivized, encourages the user to use the tool in place of research and critical thinking – in place of the user's intelligence.
Thanks for listening. ~